The Geometry of Script Parsing: How Theatre Subtitles and Supertitles Detect Dialogue
Modern theatre subtitle systems depend on one critical capability: accurate cue detection from scripts.
Whether generating supertitles for opera, subtitles for stage productions, or live captions for accessibility, the system must reliably determine:
- Who is speaking
- When a line begins
- Where dialogue blocks appear in the script
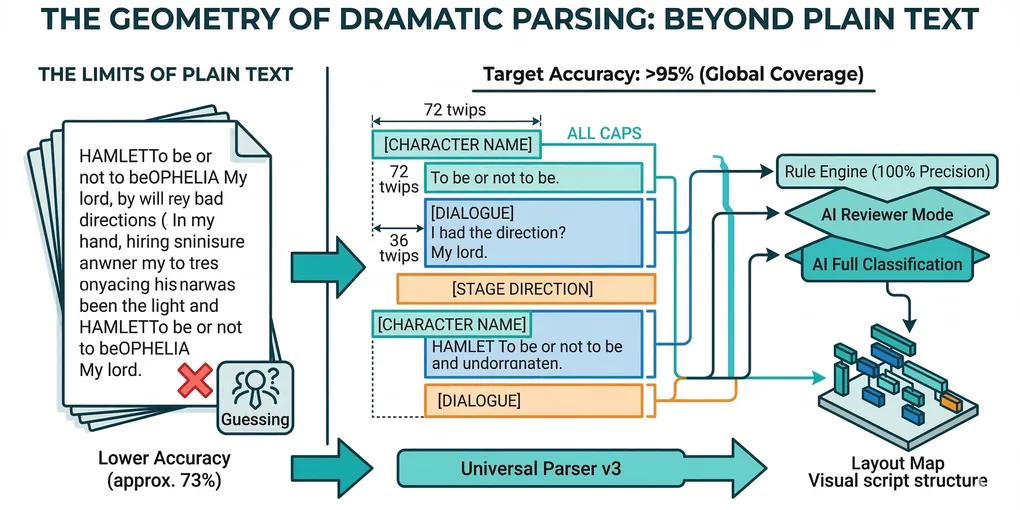
At first glance, this sounds like a natural language processing problem. In practice, it isn’t. During the development of SurtitleLive v2, we analyzed nearly 100 scripts from different languages and theatrical traditions. That process led us to a surprising conclusion: A theatre script is not primarily linguistic data. It is spatial data.
1. The Western Script Problem: Structure without Punctuation
A typical English theatrical script relies on layout conventions rather than punctuation to define roles.
Example: A typical stage script layout
HAMLET
To be, or not to be: that is the question.OPHELIA
My lord, I have remembrances of yours.
For a human reader, the interpretation is obvious:
| Block | Interpretation |
|---|---|
| HAMLET | Character name |
| Indented text | Dialogue |
| OPHELIA | Character name |
But for a parser that only sees plain text, the structure disappears. We recognize the patterns because character names appear in ALL CAPS, dialogue is indented, and blocks are separated by vertical spacing. The grammar of Western scripts is typographic, not linguistic.
2. From Script Blocks to Subtitle Cues
In a live performance environment, subtitle software does not simply display text. It must convert a script into a sequence of subtitle cues.
Each detected dialogue block becomes a subtitle cue that can be triggered during a live performance. If the parser misidentifies a dialogue block, the subtitle system will trigger the wrong cue—a failure that is unacceptable in live theatre.
3. Punctuation vs. Layout: A Cross-Language Discovery
Performance varies dramatically depending on the language’s reliance on explicit vs. implicit markers.
Chinese / Cantonese: Punctuation-Driven
Chinese theatrical scripts often encode structure explicitly:
張三:今天下雨。 (Zhang San: It is raining today.)
李四:真的嗎? (Li Si: Really?)
(他們望向窗外) ((They look out the window.))
| Pattern | Classification |
|---|---|
| 角色:台詞 (Character: Dialogue) | Dialogue |
| (…) (Parentheses) | Stage direction |
This punctuation-driven structure makes parsing almost trivial compared to Western formats.
Parsing Reliability Patterns (2026-03)
| Language / Format | Structural Signal | Common Bottleneck |
|---|---|---|
| Chinese / Cantonese | Explicit punctuation (角色:台詞) | Format consistency |
| Japanese | Stable quotation markers | Minor formatting variations |
| English (US/UK) | Implicit layout structure | Indentation and capitalization |
| German / French | Complex theatrical formatting | Ambiguous block boundaries |
4. The Hidden Cost of Converting Scripts to Plain Text
Many subtitle systems process scripts by first converting documents to plain text, stripping away layout information.
Original formatted script:
HAMLET
To be or not to be
After plain text conversion:
HAMLET To be or not to be
Without indentation or block boundaries, the parser must rely on semantic guessing to determine whether “HAMLET” is a character name or part of the sentence.
5. The Architectural Pivot: Layout-First Parsing
Instead of asking “What does this sentence mean?”, the machine asks: “What does this text block look like geometrically?”
By using OOXML extraction from .docx files, we retrieve precise layout attributes like indentation (measured in twips), capitalization flags, and paragraph styles.
Example: Layout signals extracted from a script
Block A:
indent = 72pt,caps_ratio = 1.0,line_length = 8- → Classified as Character
Block B:
indent = 36pt,caps_ratio = 0.2,line_length = 48- → Classified as Dialogue
6. Stage Directions: When Typography Becomes Structure
In many theatrical scripts, stage directions are indicated purely through typography—often italics.
Example: Typography as Structure
HAMLET
To be, or not to be.He pauses and looks toward the audience.
OPHELIA
My lord?
| Block | Interpretation |
|---|---|
| HAMLET | Character name |
| Indented sentence | Dialogue |
| Italic text | Stage direction |
Once formatting disappears, the parser cannot distinguish between dialogue and narrative. Some scripts use even more minimal italic notes:
pause
turns away
These contain almost no linguistic cues, relying 100% on typographic style attributes like italic=true.
7. A Three-Tier AI Model for Reliable Cue Detection
We repositioned AI as a reviewer rather than a guesser:
- Tier 1 — Deterministic Rules: Handles clearly marked formats through deterministic parsing rules before ambiguity handling begins.
- Tier 2 — AI Review: Acts as a proofreader to validate uncertain classifications.
- Example:
HAMLET (quietly). The system determines if “(quietly)” is a stage direction or dialogue based on document context.
- Example:
- Tier 3 — AI Classification: Full classification for highly ambiguous regions, anchored by layout patterns found elsewhere in the same document.
Conclusion
Theatre scripts appear simple, but their meaning emerges from spatial organization. By moving from semantic guessing to layout-first parsing, SurtitleLive helps prepare cue structures that operators can review and trigger during performance.
FAQ
Q: What is a subtitle cue in theatre?
A: A subtitle cue is the moment when a line of dialogue should appear on the subtitle display. Cue detection requires identifying dialogue blocks and speaker transitions within the script.
Q: How does the system handle inconsistent formatting?
A: Our system clusters similar layouts. If a document profile changes, the parser performs Layout Segmentation to adapt its strategy in real-time.
Q: Why is layout important when parsing scripts for subtitles?
A: Many scripts use indentation and spacing instead of punctuation to encode structure. A layout-first parser detects cues more reliably than semantic models alone.